Wissensdatenbank (Knowledge Base)
Was ist die Wissensdatenbank?
Die Wissensdatenbank ermöglicht es Ihrem Voice-Agenten, auf spezifische Wissensdatenquellen zuzugreifen. Sie können PDFs, URLs oder Textdokumente hochladen, und Ihr Agent nutzt diese Informationen automatisch während der Gespräche. Diese Informationen erweitern das Wissen Ihrer KI über spezifische Themen und ermöglichen präzisere, relevantere Antworten. Während KI-Modelle über ein breites Grundwissen verfügen, können sie durch zusätzliche Datenquellen mit aktuellen oder spezialisierten Informationen angereichert werden. Neu in Version 2.0: Moderne Toggle-basierte Aktivierung, Echtzeit-Token-Überwachung und Prompt-Vorschau für Voice-Agenten.Wo finde ich die Wissensdatenbank?
1. Hauptnavigation (Linke Seitenleiste)
In der linken Seitenleiste finden Sie den Eintrag “Wissensdatenbank”. Hier können Sie alle Datenquellen zentral verwalten (hochladen, anzeigen, bearbeiten, löschen).2. Voice Wizard - Wissensdatenbank Tab
Im Voice Wizard gibt es einen Tab “Wissensdatenbank”, wo Sie auswählen können, welche Datenquellen für Ihren spezifischen Voice-Agenten aktiviert werden sollen.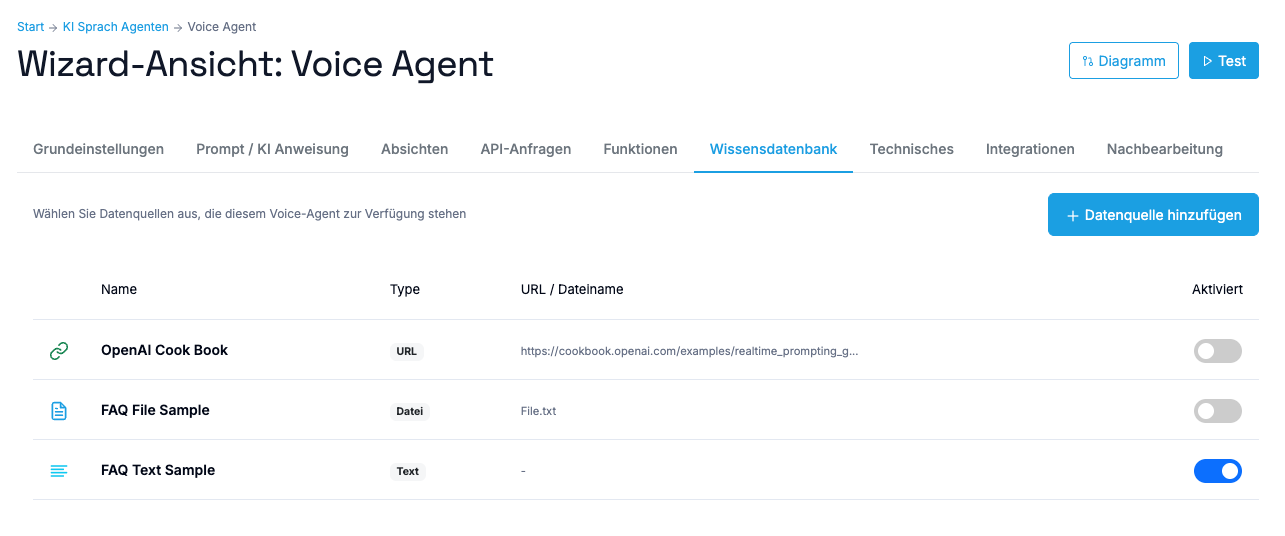
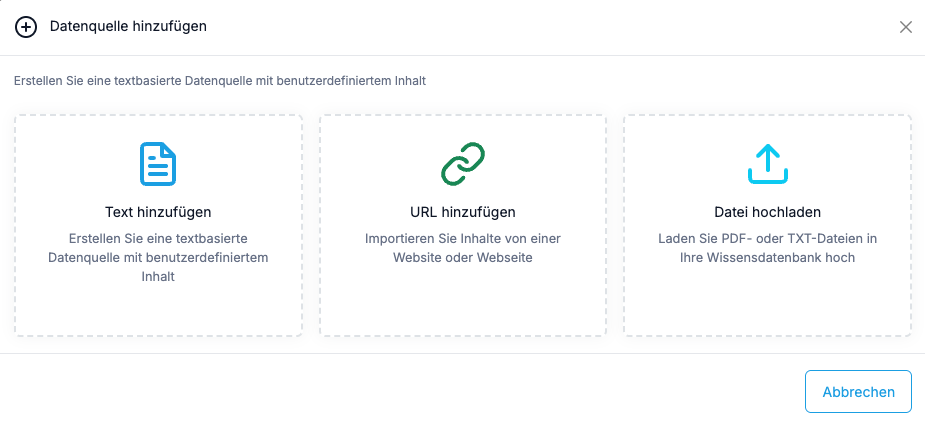
Datenquellen hochladen
Es gibt 3 Möglichkeiten, Wissen hinzuzufügen:1. PDF/TXT Datei
- Max. Dateigröße: 15 MB
- Max. Textinhalt: Grob ungefähr 20-30 Textseiten (abhängig von Formatierung und Textdichte)
- Wichtig: Verwenden Sie qualitativ hochwertige PDFs mit klarem, extrahierbarem Text. Eingescannte Bilder oder Dokumente ohne echten Text können nicht verarbeitet werden.
2. Webseite (URL)
- Automatisches Scraping (Herunterladen und Auslesen) des Webseiten-Inhalts
- Max. Textinhalt: Grob ungefähr 20-30 Textseiten extrahierter Inhalt
3. Manueller Text
- Direkte Texteingabe im Textfeld
- Max. Textinhalt: Grob ungefähr 8.000 - 12.000 Wörter
Datenquellen für Voice-Agenten aktivieren
So verbinden Sie eine Datenquelle mit Ihrem Voice-Agenten:- Gehen Sie zu Voice Wizard → Wissensdatenbank Tab
- Finden Sie die gewünschte Datenquelle in der Liste
- Aktivieren Sie den Toggle-Schalter (Umschalter) neben der Datenquelle
- Der Kontext wird automatisch zum Ende Ihres Haupt-Prompts hinzugefügt und formatiert wie folgt:
Token-Limits & Empfehlungen
Was sind Tokens? Tokens sind die Einheiten, in denen KI-Modelle Text verarbeiten. Ein Token entspricht ungefähr:- 🇩🇪 ~1,5 Tokens pro deutsches Wort
- 🇬🇧 ~1,3 Tokens pro englisches Wort
- Beispiel: 6.000 deutsche Wörter ≈ 9.000 Tokens (ungefähr)
🟡 Empfohlene Grenze: ~9.000 Tokens
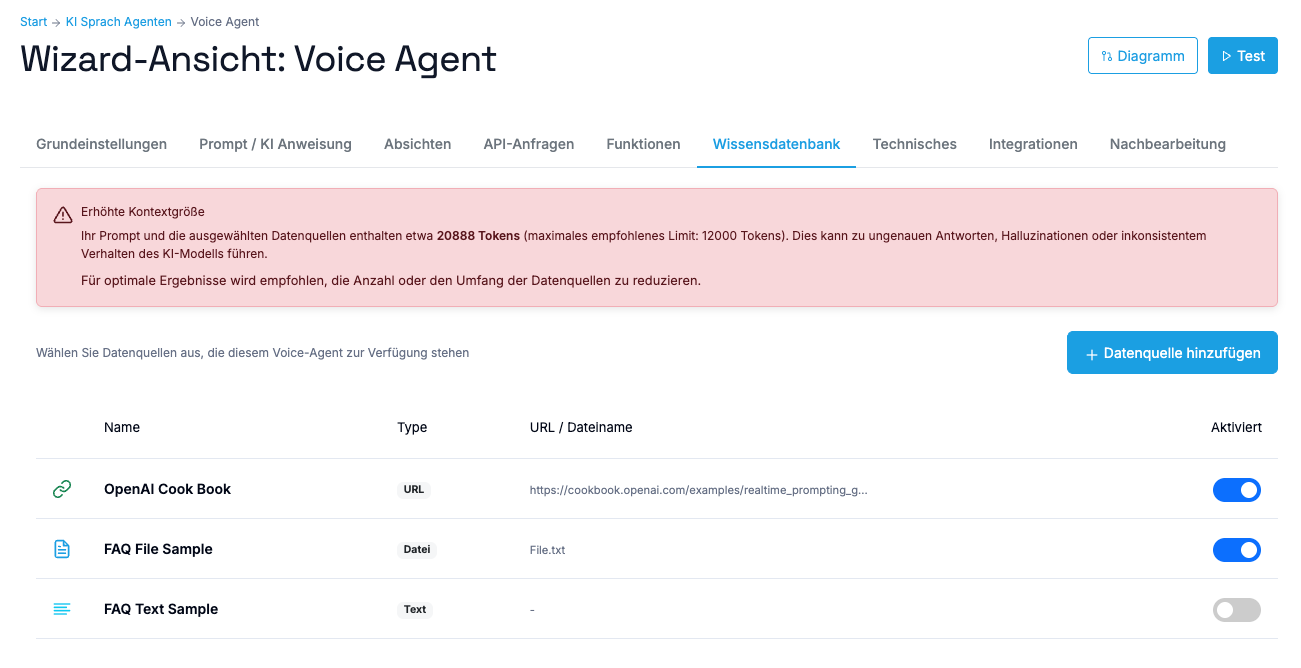
Wenn Ihr Haupt-Prompt (der von Ihnen geschriebene Basis-Prompt) zusammen mit allen aktivierten Datenquellen ungefähr 9.000 Tokens überschreitet, erscheint ein gelber Hinweis im Voice Wizard.🔴 Empfohlene Obergrenze: ~12.000 Tokens
Bei mehr als 12.000 Tokens erscheint ein roter Hinweis. Warum diese Grenzen?- Bei zu großem Kontext kann die KI Schwierigkeiten haben, alle Informationen korrekt zu verarbeiten
- Die Antwortqualität kann sinken – die KI könnte ungenaue oder irrelevante Informationen liefern
- In extremen Fällen kann die KI anfangen zu “halluzinieren” (falsche Informationen erfinden)
- Diese Grenzen basieren auf unserer Erfahrung für optimale Ergebnisse und präzise Antworten
- Dies sind Empfehlungen, keine festen technischen Limits
- Sie können selbst entscheiden, wie viele Datenquellen Sie aktivieren möchten
- Die Hinweise dienen als Orientierungshilfe für beste Ergebnisse
- Um die Qualität der Antworten zu gewährleisten, wird verhindert, dass Sie einzelne Datenquellen hochladen, die bereits die rote Grenze überschreiten
- Hinweis: Die Token-Limits (9.000 / 12.000) sind bei Bedarf konfigurierbar – kontaktieren Sie uns, falls Sie individuelle Anpassungen benötigen
✅ Best Practices für optimale Ergebnisse
| ✅ | Verwenden Sie gut strukturierte Dokumente mit klaren Überschriften und Absätzen |
| ✅ | Entfernen Sie redundante Informationen aus Ihren Datenquellen |
| ✅ | Prüfen Sie die Token-Hinweise regelmäßig, besonders nach dem Hinzufügen neuer Quellen |
| ✅ | Aktivieren Sie nur relevante Datenquellen für den jeweiligen Agenten |
| ❌ | Laden Sie keine minderwertigen/unlesbaren PDFs hoch |
| ❌ | Aktivieren Sie nicht alle Datenquellen gleichzeitig, wenn nicht nötig |

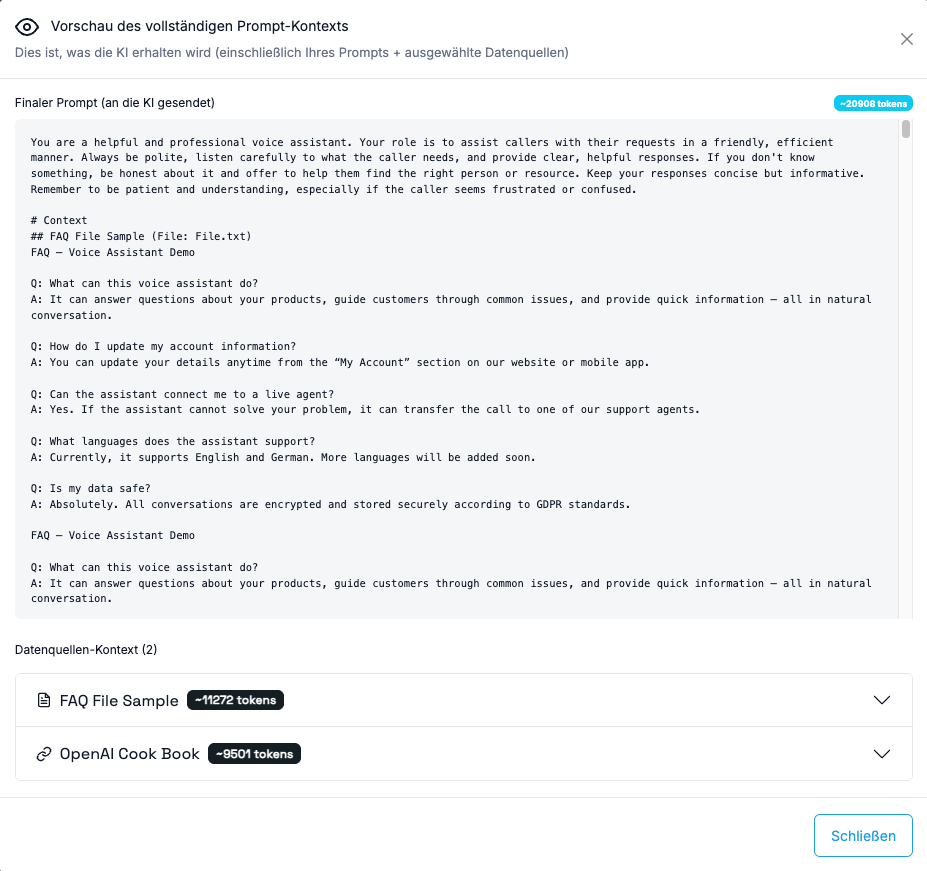
Prompt-Vorschau
Neues Feature: Sie können jetzt den vollständigen Prompt inklusive aller aktivierten Datenquellen anzeigen lassen. So geht’s:- Im Voice Wizard → Prompt-Bereich
- Klicken Sie auf den “Vorschau”-Button
- Ein Modal-Fenster zeigt den vollständigen Kontext, der an die KI gesendet wird
%%context:name%% Syntax wird in der Vorschau nicht angezeigt.
Wichtig: Umstellung der Datenquellen-Integration
Alt (wird eingestellt):
Neu (empfohlen):
Verwendung des Wissensdatenbank-Tabs im Voice Wizard mit Toggle-basierter Aktivierung.📅 Zeitplan:
| Datum | Status |
|---|---|
| Oktober 2025 | ✅ Bereits umgesetzt: Die Hinweise für %%context:name%% wurden aus dem Prompt Builder entfernt. Sie sehen diese Syntax nicht mehr in der Benutzeroberfläche. |
| Jetzt - 1. Nov 2025 | Übergangsphase: Der alte %%context:name%% Syntax funktioniert auf dem Backend noch. Ihre bestehenden Prompts arbeiten weiterhin normal. |
| Ab 1. November 2025 | 🔴 Abschaltung: Der %%context:name%% Syntax wird vollständig deaktiviert. Bitte migrieren Sie Ihre Prompts vor diesem Datum! |
Migration in 3 einfachen Schritten:
Schritt 1: Datenquellen überprüfen
Gehen Sie zu Wissensdatenbank in der linken Navigation und überprüfen Sie Ihre vorhandenen Datenquellen.
Wenn Sie bisher
%%context:faq%% verwendet haben, sollten Sie eine Datenquelle mit dem Namen “faq” finden.Schritt 2: Prompt bereinigen
Entfernen Sie alle Nachher:
%%context:...%% Platzhalter aus Ihrem Prompt.Vorher:Schritt 3: Datenquellen im Wizard aktivieren
Gehen Sie zu Voice Wizard → Wissensdatenbank Tab und aktivieren Sie die gewünschten Datenquellen mit dem Toggle-Schalter (ein/aus).
Vorteile der neuen Methode:
| Feature | Beschreibung |
|---|---|
| 📊 Token-Überwachung | Echtzeit-Hinweise, wenn der Kontext groß wird |
| 👁️ Vorschau | Sehen Sie genau, was an die KI gesendet wird |
| 🎛️ Flexibilität | Aktivieren/Deaktivieren Sie Quellen ohne Prompt zu ändern |
| 🧹 Sauberkeit | Keine “Magic Syntax” mehr im Prompt |
Häufige Fragen
Warum wird meine große PDF-Datei nicht hochgeladen?
Warum wird meine große PDF-Datei nicht hochgeladen?
Der Upload wird abgelehnt, wenn eine der folgenden Bedingungen überschritten wird:
- Dateigröße: Mehr als 15 MB
- Extrahierter Textinhalt: Zu viel Text für eine einzelne Datenquelle (grob ungefähr mehr als 20-30 Textseiten)
Kann ich PDF-Dokumente mit Bildern verwenden?
Kann ich PDF-Dokumente mit Bildern verwenden?
Ja, Sie können PDFs mit Bildern hochladen. Das System extrahiert automatisch den vorhandenen Text aus dem PDF.Wichtig zu beachten:
- Es wird nur echter Text aus dem PDF extrahiert (z.B. Text, der mit einem Text-Editor erstellt wurde)
- Text, der nur als Bild im PDF eingebettet ist (z.B. gescannte Seiten ohne OCR), kann nicht ausgelesen werden
- Bilder selbst werden nicht verarbeitet – nur der Text wird verwendet
Was passiert, wenn ich zu viele Datenquellen aktiviere?
Was passiert, wenn ich zu viele Datenquellen aktiviere?
Der Agent erhält sehr viel Kontext auf einmal, und die Antwortqualität kann sinken. Die KI kann Schwierigkeiten haben, die relevantesten Informationen zu finden und präzise zu antworten.Achten Sie auf die Token-Hinweise und überlegen Sie, ob alle aktivierten Datenquellen wirklich für die aktuelle Aufgabe des Agenten notwendig sind.
Wo werden meine Daten gespeichert?
Wo werden meine Daten gespeichert?
Alle hochgeladenen Datenquellen werden zentral für Ihren gesamten Tenant (Account) gespeichert und sind für alle Benutzer in Ihrem Account sichtbar.Die Dateien und Daten werden auf Servern in der EU gespeichert und unterliegen den europäischen Datenschutzbestimmungen (DSGVO).
Wo finde ich meine alten %%context:...%% Datenquellen?
Wo finde ich meine alten %%context:...%% Datenquellen?
Alle vorhandenen Datenquellen sind weiterhin in der Wissensdatenbank verfügbar. Sie müssen nur im Voice Wizard über den Toggle-Schalter aktiviert werden, statt sie im Prompt zu referenzieren.
Kann ich sehen, welche Datenquellen gerade aktiv sind?
Kann ich sehen, welche Datenquellen gerade aktiv sind?
Ja, es gibt zwei Möglichkeiten:
- Im Voice Wizard → Wissensdatenbank Tab: Alle aktivierten Datenquellen haben den Toggle-Schalter auf “ON” (eingeschaltet)
- Prompt-Vorschau: Zeigt den vollständigen Kontext mit allen aktivierten Datenquellen, genau so wie er an die KI gesendet wird
💡 Tipp: Nutzen Sie die Prompt-Vorschau, um zu verstehen, wie Ihr finaler Prompt mit allen Datenquellen aussieht. Das hilft Ihnen, Redundanzen zu erkennen und die Qualität zu optimieren!